
Building a Layered Defense Against Web Scraping
No se pudo agregar al carrito
Add to Cart failed.
Error al Agregar a Lista de Deseos.
Error al eliminar de la lista de deseos.
Error al añadir a tu biblioteca
Error al seguir el podcast
Error al dejar de seguir el podcast
Building a Layered Defense Against Web Scraping
-
Narrado por:
-
De:
This story was originally published on HackerNoon at: https://hackernoon.com/building-a-layered-defense-against-web-scraping.
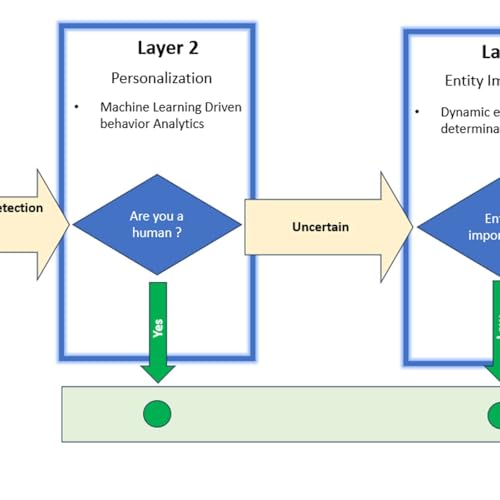
Discover how a three-layer data-protection model blends AI, risk-based gating, and legal context to stop web scraping while preserving user trust.
Check more stories related to data-science at: https://hackernoon.com/c/data-science. You can also check exclusive content about #web-scraping, #data-protection, #ai-security, #product-strategy, #web-scraping-protection, #bot-mitigation, #risk-based-gating, #data-security-strategy, and more.
This story was written by: @areejit1. Learn more about this writer by checking @areejit1's about page, and for more stories, please visit hackernoon.com.
The web-scraping industry is no longer niche. Valued at USD 1.03 billion in 2025, it is projected to nearly double by 2030. Traditional defenses rate limiting, CAPTCHAs, IP bans are brittle against modern toolkits. A layered defense acknowledges this tension.