
OpenVision 3 Challenges the Need for Separate Vision and Image Generation Models
No se pudo agregar al carrito
Add to Cart failed.
Error al Agregar a Lista de Deseos.
Error al eliminar de la lista de deseos.
Error al añadir a tu biblioteca
Error al seguir el podcast
Error al dejar de seguir el podcast

OpenVision 3 Challenges the Need for Separate Vision and Image Generation Models
-
Narrado por:
-
De:
This story was originally published on HackerNoon at: https://hackernoon.com/openvision-3-challenges-the-need-for-separate-vision-and-image-generation-models.
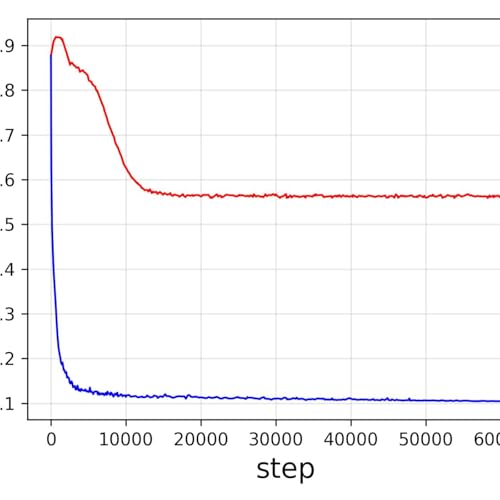
OpenVision 3 introduces a unified visual encoder that supports both image understanding and generation, reducing redundancy across vision AI systems.
Check more stories related to machine-learning at: https://hackernoon.com/c/machine-learning. You can also check exclusive content about #multimodal-ai, #generative-vision-ai, #computer-vision-models, #vision-language-models, #ai-image-generation, #openvision-3, #vision-language-learning, #multimodal-foundation-models, and more.
This story was written by: @aimodels44. Learn more about this writer by checking @aimodels44's about page, and for more stories, please visit hackernoon.com.
OpenVision 3 demonstrates that a single visual encoder, using a unified tokenizer, can effectively power both image understanding and image generation tasks across multiple model sizes.